


Raclons le web
Maintenant que vous connaissez les sélecteurs, commençons par automatiser une petite recherche sur Google. Reprenons le code suivant:
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
driver = webdriver.Chrome("D:Mon DrivePythonTestchromedriver.exe")
driver.get("http://www.google.ca/")
Ouvrez Google et inspectez la page pour trouver le champ (input) de recherche:
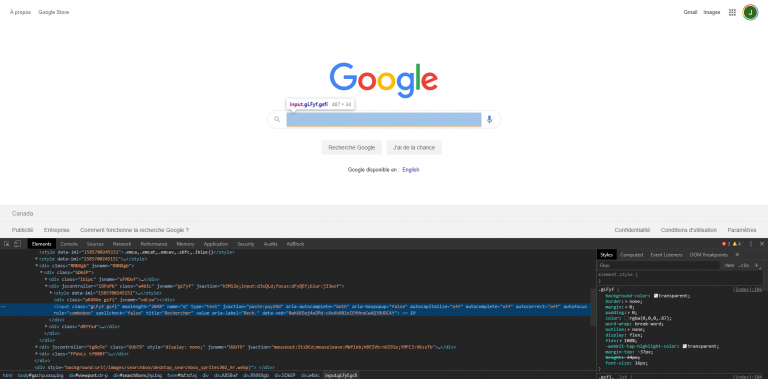
Ce champ contient l’attribut name ayant pour valeur « q », que nous pouvons donc utiliser pour le sélectionner:
selection = driver.find_element_by_name("q")
Nous avons donc créé une variable nommée « selection » qui contient notre barre de recherche. Nous pouvons maintenant utiliser la méthode « send_keys » de l’objet « selection » pour utiliser notre clavier, écrire, puis lancer la recherche avec « Entrer»:
#Code complet jusqu'à maintenant
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
driver = webdriver.Chrome("D:Mon DrivePythonTestchromedriver.exe")
driver.get("http://www.google.ca/")
selection = driver.find_element_by_name("q")
selection.send_keys("Historiamatica")
selection.send_keys(Keys.ENTER)
Mon code me renvoie donc ma recherche. Mais, j’aimerais pouvoir cliquer toujours sur le premier lien… Comment faire? Et bien, vous devrez ouvrir votre navigateur web et essayer vous-même de faire une recherche. Faites un clic droit sur le premier élément, puis inspectez-le:
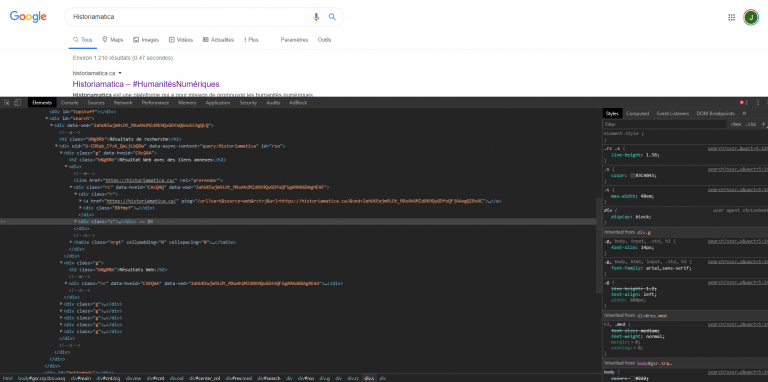
Comme vous pouvez peut-être le constater, chaque résultat de recherche est contenu dans une div avec la class «g», et le lien dans un sous-div nommé «r». Pour faciliter la recherche, utilisons le xpath de l’élément. Pour le trouver, rien de plus simple, faites un clic droit sur la balise « a », puis «Copy» et finalement «Copy XPath». On peut alors sélectionner l’élément avec notre variable « selection » et l’attribut find_element_by_xpath:
selection = driver.find_element_by_xpath("//*[@id='rso']/div[1]/div/div/div[1]/a")
Puis, on peut utiliser la méthode « click » pour cliquer sur le lien:
selection.click()
Vous connaissez maintenant les bases pour racler le web. Puisqu’il s’agit d’un cours d’introduction nous n’irons pas beaucoup plus en détail dans l’utilisation de Selenium, sachez seulement que les possibilités sont infinies (ou presque). En guise de conclusion, nous vous proposons le code qui suit, une version plus poussée de ce que nous avions commencé à faire:
# Importation des différents modules
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import csv
driver = webdriver.Chrome("D:Mon DrivePythonTestchromedriver.exe") # Initialisation du webdriver de Chrome
driver.get("http://www.google.ca/") # Naviguer vers Google
selection = driver.find_element_by_name("q") # Création du sélection de la barre de recherche ayant pour nom « q »
selection.send_keys("Histoire Strasbourg") # Écrire du texte dans la barre de recherche
selection.send_keys(Keys.ENTER) # Appuyer sur Entrer
i = 0 # Initialisation du compteur de page
nb = 0 # Initialisation du compteur de liens
with open('resultats.csv', 'w', newline='', encoding='utf-8') as fichier: # Ouverture du fichier resultats.csv en mode écriture
lienAjout = csv.writer(fichier, delimiter=';')
print("Début de la recherche")
while i <= 100: # Boucle pour faire le tour des pages
try: # Vérifier si les instructions suivantes fonctionnent
suivant = driver.find_element_by_id("pnnext") # Sélectionner le bouton Suivant (id: pnnext) sur la page
selection = driver.find_elements_by_css_selector("#rso a") # Sélectionner tous les liens contenus dans la balise #rso
for lien in selection: # Boucle pour faire le tour des liens provenant de la page
texte = lien.get_attribute("text").lstrip() # Création d'une variable pour contenir le titre, en enlevant les espaces inutiles.
if texte != "Traduire cette page" and texte != "En cache" and texte != "" and texte != "Similaires": # On vérifie que le titre du lien ne soit pas l'un de ceux ici
lienAjout.writerow([str(lien.get_attribute("text")), str(lien.get_attribute('href'))]) # Écriture des données dans le fichier CSV
nb+=1 # On ajoute 1 au compte des liens
print(nb) # On imprime le compte
suivant.click() # On clique sur le lien « Suivant »
except: # Si une erreur est survenue, on arrête la boucle en imposant la valeur de 100 à i
i = 100
i+=1 # On ajoute 1 au compteur de page
print("Fin de la recherche. " + str(nb) + " liens trouvés lors du processus")
Ce code ne sera pas expliqué en détail, mais nous vous l’avons commenté, et, voici un petit résumé du processus:
- Ouvrir le navigateur
- Naviguer vers Google
- Rechercher « Histoire Strasbourg »
- Ouvrir/créer un fichier CSV nommé résultat
- Sélectionner les liens dans les résultats
- Vérifie s’il s’agit d’un lien de site web, et non pas d’un lien Google pour traduire la page, accéder à la cache ou du contenu similaire
- S’il s’agit bien d’un lien, ajouter une ligne à nos CSV, incluant le texte du lien et le lien en soi.
- On fait de même pour les 100 premières pages de résultats, ou bien jusqu’à la dernière page.
- De plus, on compte le nombre d’éléments
Voici une petite démonstration en vidéo: